LLM Fine-tuning using the Distributed Private Data


Recently, Large Language Models (LLM), such as ChatGPT, have gained tremendous attention in academia and industry communities. Comparing to the previous GPT-2 and BERT models, the results achieved by ChatGPT are truly impressive.
The training of LLM demands large scale computational power and extensive data requirements. The training requires a data center with thousands of professional graphic card such as Nvidia A100. And it is not only about the cards, the data transfer speed between the cards also has a great impact on the training speed. A slightly less faster on the connection could cause a delay of months on a single training iteration.
The limitation on the hardware closes the door of participating to the vast majority. Only a few individual researchers could get enough resources to do the experiment. The cost to customize an LLM and deploy it as a service is also unacceptable for most of the enterprises.
In addition to the hardware requirements, the data, especially high quality data, that is required to train LLM is also massive. The only source of the corpus used for recent LLMs is the open Internet, and it is running out. According to a prediction made by six computer scientists in their paper titled "Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning," the availability of high-quality language data, necessary for training models like ChatGPT, is projected to diminish before 2026.
When the corpus from the public domain becomes scarce, it becomes crucial to explore and utilize the private data from individuals and businesses. However, leveraging such data comes with a lot of challenges related to the security and privacy. The owner will never allow their private valuable data to be leaked to the public.
Privacy-Preserving-Computation (PPC) technologies, such as Federated Learning and Multi-Party Computation, will play an important role in this area. Which allows models to be trained on decentralized data without directly accessing or compromising the privacy of the individual data sources. These approaches strive to strike a balance between utilizing private data and preserving data ownership and privacy rights.
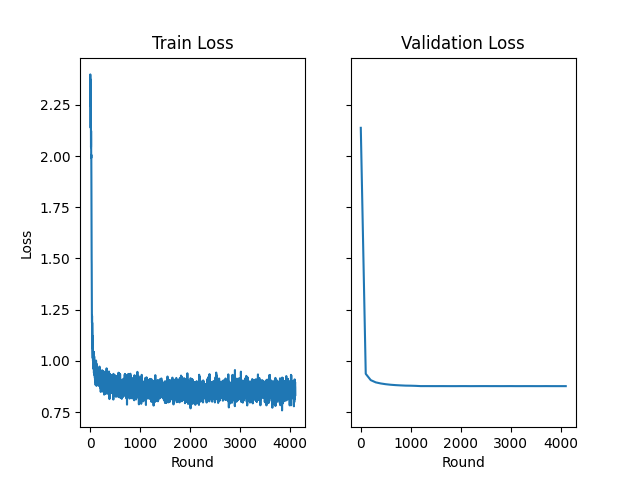
At Crynux, the Federated Task Framework has fully supported the training of LLMs on the private data that is distributed across several nodes. The training is coordinated by the Blockchain. The data is kept private for each of the nodes thanks to the Federated Learning. The developer gets the model at the end of the training, and nothing more.
For the Crynux developers, it is super easy to write an LLM training task under the provided toolkits. There is no need to know a single bit about the details underneath. Just write the training task in the traditional way, and leave the rest to the Crynux Network.
Check this LLM example that is trained under Crynux Network. The network is composed of 3 separated nodes. 2 of them are virtual nodes sharing a single Nvidia A100 card, and the other one uses an RTX 4090. The machines are inside 2 data centers located at different places.
Alpaca is an instruction-based large language model developed by Stanford University. It is built upon the LLAMA 7B model from Meta and fine-tuned using an instruction dataset. According to Alpaca's data, fine-tuning the LLAMA 7B model requires eight 80GB A100 graphics cards and takes approximately three hours.
Eight A100s are still not acceptable for the average user. The Low-Rank Adaptation (LoRA) technique addresses this issue, which makes it possible to fine-tune LLMs on a single consumer-level graphic card. Alpaca-LoRA is a project to train Alpaca using LoRA, which is also what we have used to train the example model using Blockchain-coordinated Federated Learning.
The dataset used was the default 52k instruction dataset provided by Alpaca. The dataset was randomly divided into 3 parts, and deployed separately on the 3 Crynux nodes. 10% of the dataset was selected as the validation set on each node, and the rest was used as the training set.
The hyper-params were kept the same as the official ones from Alpaca-LoRA. The LLAMA 7B base model was from decapoda-research/llama-7b-hf on HuggingFace.
The batch size was set to be 128. 16GB of graphic memory was consumed on each node.
After 10 epochs that have lasted for around 24 hours, here's what we got:
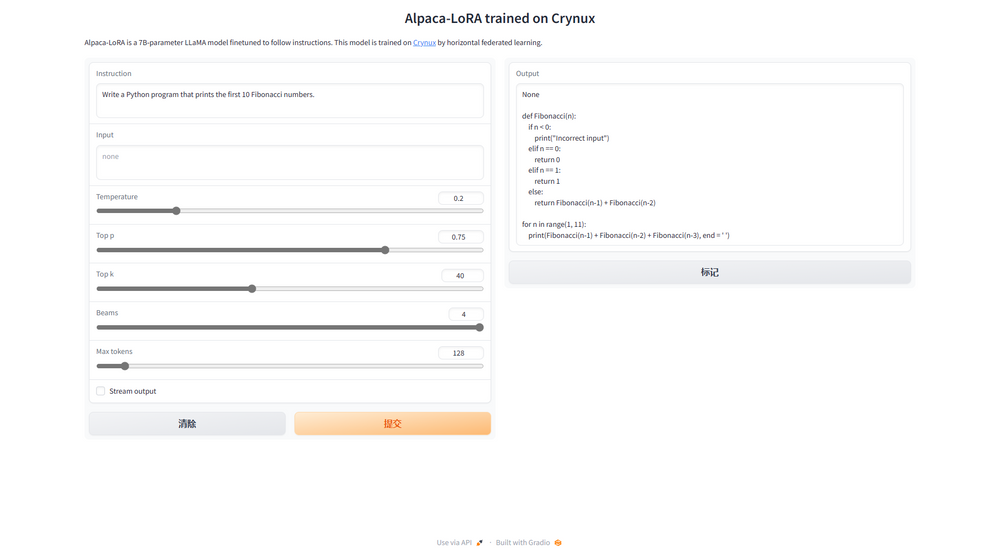
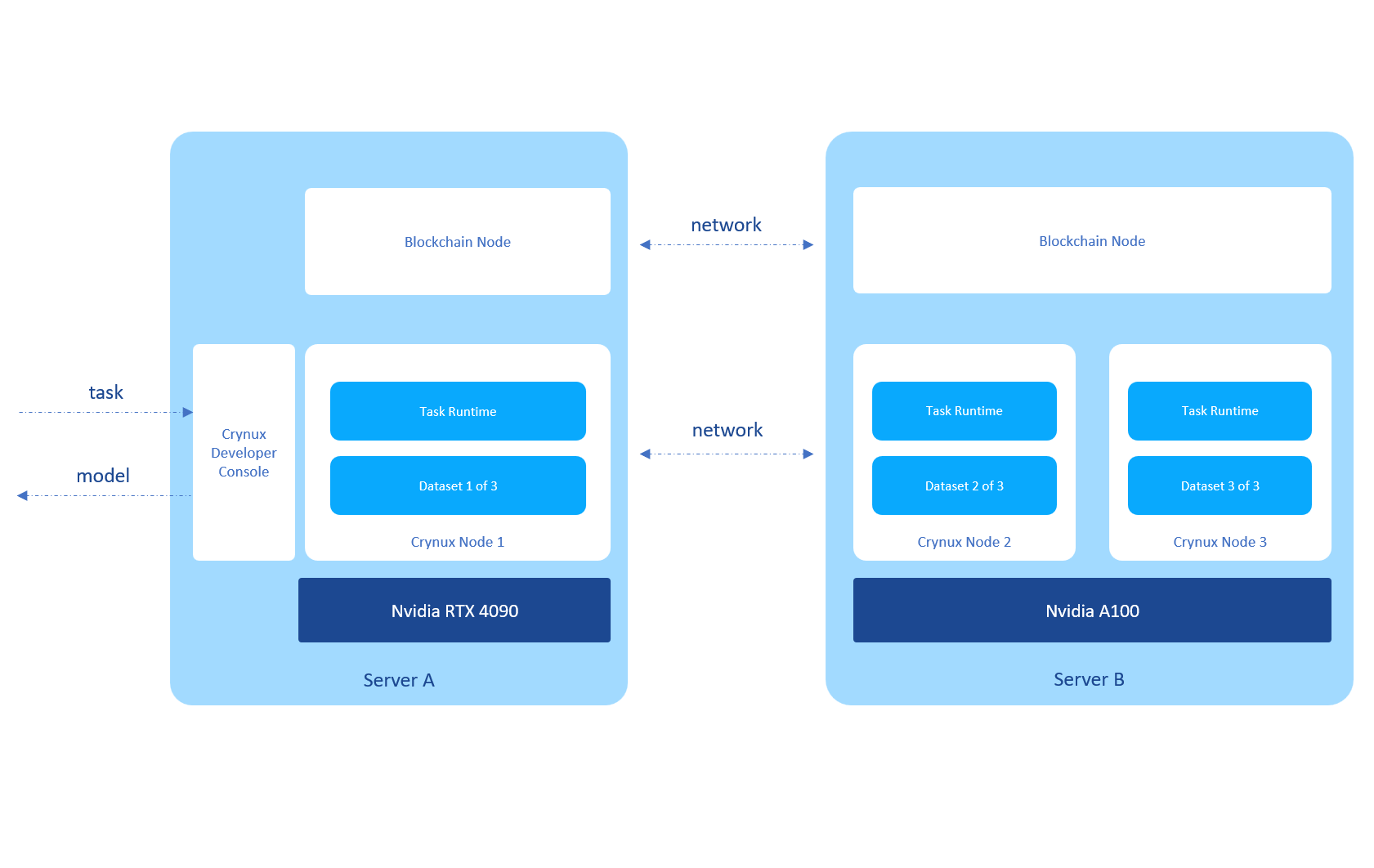
Let's ask the LLM to write some Python codes to print the Fibonacci numbers. The output looks promising. And let's ask it about the history of the king of France in 2019. Again we got the correct answers!
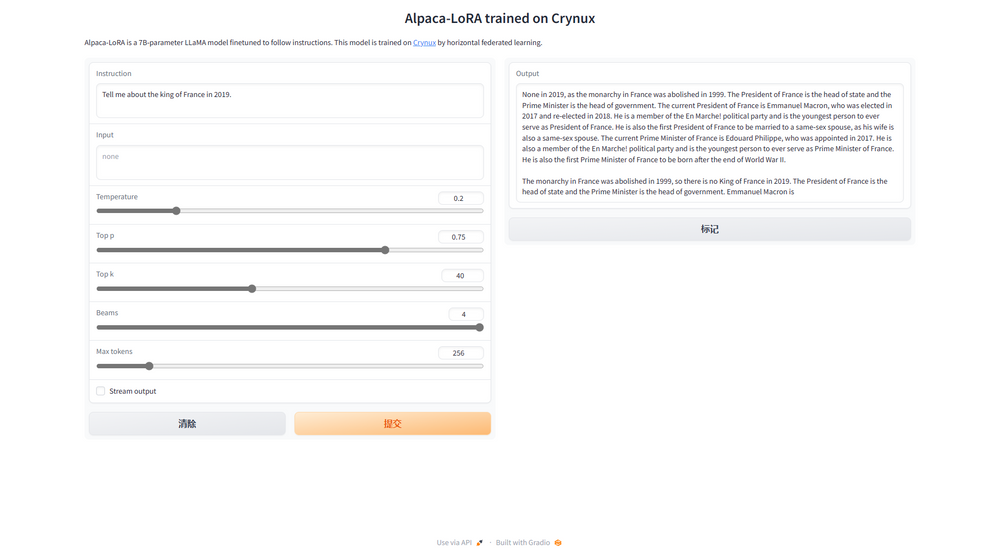
And here's the loss changes on both the training dataset and the validation dataset: