Stable Diffusion Workflow Reimagined: Cheap, Flexible and more Powerful


Stable Diffusion and AIGC has become a groundbreaking tool that has transformed the landscape of various industries, offering unprecedented benefits and opportunities.
Being an open source solution, the original Stable Diffusion models are freely accessible to the public. The open source toolkits around the models, such as the web user interface, are developing rapidly as well. More and more pretrained and LoRA models are published online for others to download and use directly. The ecosystem around Stable Diffusion is evolving fast.
Despite the growing on the size of the Stable Diffusion community, there are still obstacles that prevent the adoption of such AIGC tools to the vast majority.
Expensive GPU is required just to begin
The requirement to run the Stable Diffusion tools for an Nvidia graphic card, although not as high as for LLMs, is still mandatory. At least a consumer level RTX card that supports CUDA must be provided. Given that most of the laptops are equipped with the integrated graphic cards, it is not possible for them to use Stable Diffusion locally. Yes, you can of course run the image generation using CPUs, but you will eventually give it up after minutes and minutes of waiting.
The learning curve is really steep
Even with the help of the stable-diffusion-webui, it is still too easy to get lost in the huge amount of concepts and parameters for beginners. The pretrained model, the LoRA model and the ControlNet model should all be downloaded and placed at different places, the LoRA network plugin and ControlNet plugin must be installed and the corresponding keywords and weights must be added to the prompt.
After the installation, it is now time to step into the ocean of the hyper-parameters tuning. It is hard even for AI professionals to know the exact meaning of all the params and to find a best combination of them to produce good images.
Now that we have mastered all the basics about Stable Diffusion. Finally! Welcome to the area of the prompt engineering. The images we get highly depends on the prompt given, in an unpredictable way. There are quite some guidelines and best practices to learn on how to setup the prompt, it still feels like rolling a dice most of the time.
The quality of the open source models is low
Even at its best setup, the images generated from the open source Stable Diffusion models are hardly acceptable for serious use cases. It might seems promising at first attempts, but there is always something missing even after tens of trails, either the whole picture is not elegant enough, or some details are incorrect and you just cannot make it right.
The limitation of the commercial platforms
Several online solutions, such as Midjourney, emerged to tackle those problems. By training private in-house models and serving them through an online service, the images generated from those platforms are finally commercial ready. By utilizing the cloud hosted GPUs, the service could be used anywhere, as long as a web browser presents.
Everything comes at a price. The cost of the cloud hosted GPUs are surprisingly high these days. No thanks to the competition of the LLM training among large enterprises. And the GPU costs are reflected in the overall costs of using the platforms.
The private in-house model is the most valuable asset to the platform. So it must be kept safe and never open to anyone. This limits the possible use cases for the platforms. The users can only use the model as is, no further customization could be made.
For example, a platform trained a private anime style model that is very good at generating images for the anime characters. And a user wants to generate an image for his favorite anime character. If, by any chance, the model is trained with the data of the character included, the user could get what he wants happily.
However, if the model is trained without those data, the image cannot be generated correctly. At such circumstance, a LoRA fine-tuning could be easily performed on the model to give the user what he wants, only a few images of the character is required. But if the model is not open to the user, and the platform does not support fine-tuning (which is the case for most existing platforms), there is nothing else the user can do.
Cheap spared GPU resources from the decentralized network
Crynux incentivizes the GPU holders to contribute their spared computing resources to others. A decentralized network is formed to connect all the GPU holders and the users. The user sends the task, such as the image generation task and the LoRA fine-tuning task, to the network. And the task is automatically dispatched to some of the GPU holders' nodes according to the node availability. After remote execution, the result is returned to the user. No more local GPU is required on the user's laptop.
The cost is calculated on the granularity of tasks. No cost for anything more than the task consumed should be paid. And since this is the spared computing resource, the users could expect a much lower price compared to the cloud hosted solutions, or buying cards themselves.
From the users perspective, the complexity of the decentralized network is completely hiding behind the applications. The user experience of a Crynux enabled application remains exactly the same as the cloud hosted ones.
Reshaped user experience from the deep integration of Crynux APIs
It is usually not the infrastructure's duty to optimize the user experience but rather the application's. However, when talking about Stable Diffusion (and other AI model services as well), how the infra is organized has a great impact on the capabilities of the downstream applications. And Crynux has been designed to give all the possibilities to the applications, allowing them to build workflows around Stable Diffusion models in anyway they could imagine.
Let's take the application Character Studio as an example, to see how exactly Crynux could be used to bring new possibilities to the Stable Diffusion ecosystem.
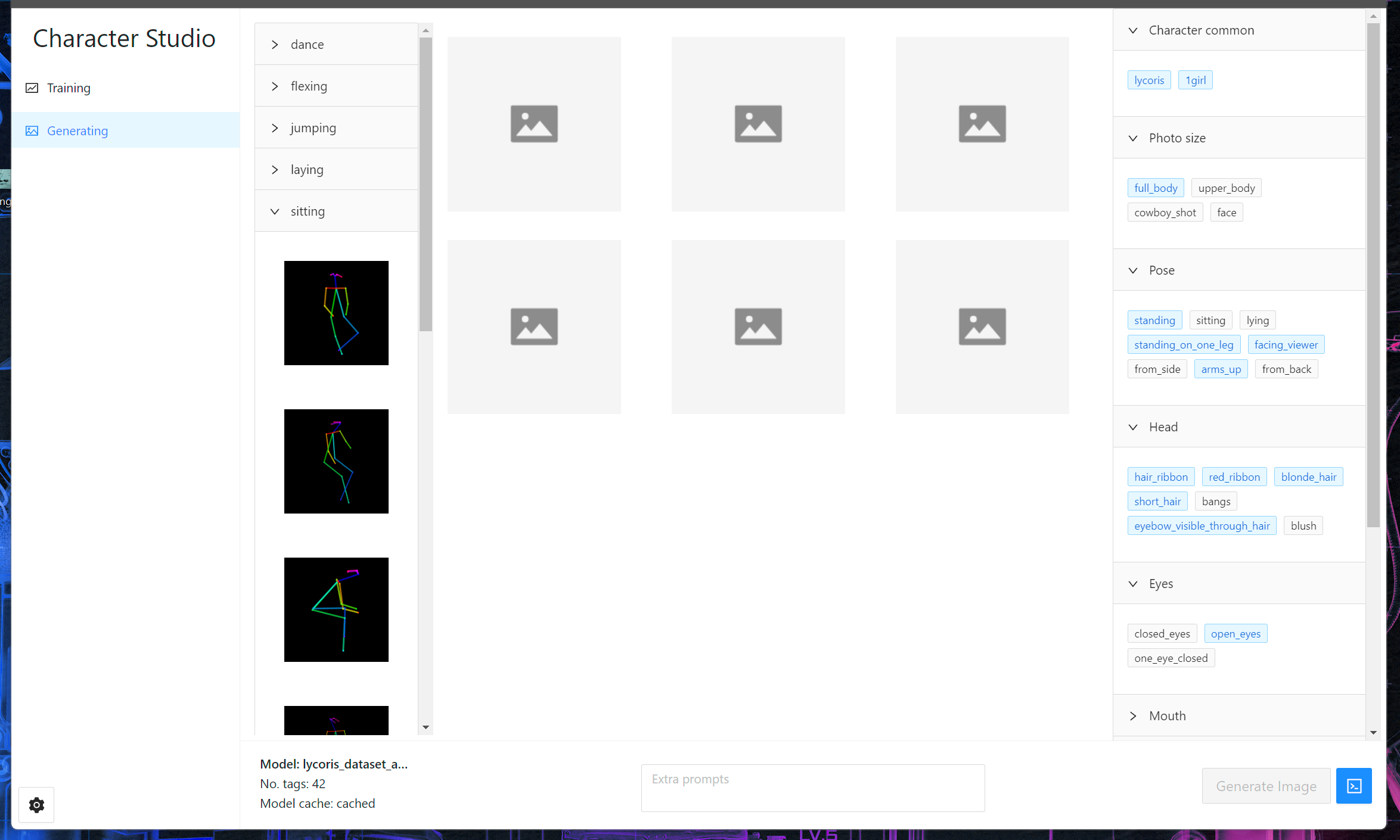
How to train a consistent image generator for the given character
Character Studio focuses on one thing: Train a (LoRA) model for a character, whether it is from the anime or a real person, and generate more images of the same character in different poses consistently.
Before Character Studio, unlike image generation, the training can only be performed by the professional, using tools like lora-scripts. For those who do not have programming or machine learning experiences but very good at learning, lora-scripts could also be used under just a few tutorials. But this is still too hard for everyone.
And for the professionals, the hardest part is "consistent". Usually one will find himself struggling on a very close image that has a key feature missing on the character. And usually the problem lies in the dataset and the annotations, which is hard to find out without hundreds of times of trail and error.
Character Studio makes it possible for everyone to train the model just by providing images and annotations as instructed. The best practices and know-hows of "consistent" is integrated into the app, transparently making the user feels like "it just works".
With the help of Crynux, Character Studio has no requirements on the hardware. It can be used either from the web browser, or as a desktop app on any laptops.
Training LoRA models upon a base model from Crynux marketplace
The training of a LoRA model requires an underlying pretrained base model. And the quality of the base model matters. If the character is from the anime, a base model that is pretrained using a lot of anime images should be used.
The high quality base models are all ready to use in the Crynux marketplace. And can be selected by the users directly in the Character Studio.
After the preparation of the dataset, select a base model, and the training could be started on the Crynux network with just one click.
Note that the base model is not downloaded to the local machine, but is served in the decentralized network. The training task is likely to be dispatched to a node that has the required base model cached for faster execution.
Generating Images using the combination of the LoRA and base models
The trained LoRA model is downloaded to the local laptop to be saved. And Character Studio supports generating images using a combination of the local saved LoRA model and a marketplace hosted base model.
Image generating using the LoRA models from the marketplace is also supported. Users could find the suitable LoRA models (and a pretrained base model) in the marketplace, and use them to generate images directly.
After the training of a model, the model could be hosted on the Crynux marketplace, to be used by others, for both image generation and fine-tuning.
One more thing: the image dataset could still make more benefits for the creator.
Although not implemented in the Character Studio (yet), but the annotated image dataset could make more benefits for the creator thanks to the private data protection technology provided by Crynux.
The creator could provide the dataset to others, to be used in their training tasks, for profit. The dataset is kept private during the whole process, the original data never leaves the owner's computer.
This is a new way for the data owners to make money from their private data, continuously, without the fear of data leakage. And the model developers get more data to produce high quality models.